← Explore
Opening Provocations
[Unk] Photos and Violent Machine Learning Datasets
Speakers:
Hito Steyerl, Alex Hanna, Maya Indira Ganesh, Nora N. Khan

PROFILE:
Hito Steyerl
Hito Steyerl is a German filmmaker and moving image artist whose work explores the divisions between art, philosophy, and politics. She has had solo exhibitions at venues including MOCA Los Angeles, the Reina Sofia, and ICA London, and participated in the Venice Biennale and Documenta. She is a Professor of New Media Art at the Berlin University of the Arts and author of Duty Free Art: Art in the Age of Planetary Civil War (2017).
Curatorial Frame:
What does the old Nazi-era Tempelhof airport have to do with current machine learning datasets? What does intelligence as common sense have to do with common sensing? In the panel discussion that opens AI Anarchies, Hito Steyerl and Alex Hanna trace histories of forgotten possibilities for anti-fascist technologies, and assess the present conditions of determinism embedded in AI. Working with Saidya Hartman’s notion of “critical fabulation”, Steyerl and Hanna discuss how we might refuse, reject, and re-imagine the sociotechnical systems we have inherited.
Soundbite:
“In the context of the larger discussion of extractivism and energy, data is one resource that can be extracted but energy and other resources—like labour—can be extracted as well.”
Hito Steyerl, setting the stage
Takeaway:
Rather than ask philosophical questions about where AI cognition and execution succeeds and fails, Steyerl looks to images of extraction and capitalism as visual evidence of the forces that really drive culture. She outlines how she’s focusing on how we do and might caption these images—largely drawing on media from the 20th century—as a way to set up a conversation about the contemporary AI prompt and the images it generates.
Soundbite:
“In the 1983 Soviet television series Acceleration, a group of cybernetic scientists try to computerize a natural gas network. At one point, they come to the conclusion that it has become sentient, en-souled. They understand it as an AI with a subjectivity of its own.”
Hito Steyerl, paraphrasing a text by Oleksiy Radynski who she is collaborating with on a Nord Stream-related research project

Reference:
The role of the Nord Stream 2 pipeline demonstrates a prime example of what Steyerl calls ‘fossil facism.’ Recently, it’s stream of natural gas forced energy-hungry Germany to cede leverage to Russia. Those tensions were exasperated by the series of explosions that ripped through both the Nord Stream 2 and 1 pipelines in September 2022, which caused leaks into international waters between Denmark and Sweden. Still uncredited, most speculation on the origins of the sabotage point to Russia, who would stand to gain the most from (further) disrupting the already strained European energy market.
Soundbite:
“What does this photo of the Nord Stream pipeline leak show? If you ask the DenseCap captioning neural network model it will give you an answer: the water is calm, the water is white, the water is brown, the water is blue.”
Hito Steyerl, linking geopolitics and machine-readability

Soundbite:
“If you ask DenseCap to analyze Bretch’s War Primer it cannot deal with it. In particular the epigram or caption, it tries to identify it as a photo and says ‘the photo is [unk].” Which I believe is an abbreviation for unknown.”
Hito Steyerl, on what happened when she fed Bertolt Brecht’s poetry book to the DenseCap captioning neural network

Reference:
Steyerl’s talk draws heavily from (and expands considerably on) Bertolt Brecht’s War Primer (1955). Described by its contemporary publisher Verso as “a devastating visual and lyrical attack on war under modern capitalism,” in it the playwright annotated conflict photography with poetry. Of particular interest to Steyerl: a seemingly benign image of coastal bathers whose extremities are stained with the oil from ships sunk in nearby naval battle, that the DenseCap captioning neural network struggles with.
Soundbite:
“If we follow Brecht’s thinking about captions: Could the AI create a caption for itself that would take into account the infrastructure of this gas network—and maybe even of itself, of its own energy extractivism? Which caption would we need for this image to capture those things that current machine learning tools are incapable of extracting from images?
Hito Steyerl, on extracting real value from images

Soundbite:
“In 2021, Vladimir Putin was the patron of an art exhibition in Berlin called ‘Diversity United.’ Outside the same building, there are now temporary homes in use by Ukrainian refugees.”
Hito Steyerl, on the politics of the Nord Stream 2 pipeline coming full circle
Soundbite:
“Both coal and oil are likely to decline as energy sources. So—instead of the famous ‘data is the new oil’ claim—what if data is the new gas?”
Hito Steyerl, quoting Radynski’s take on Wendy Chun’s 2017 claim that ‘data is the new coal’ (not oil)

Reference:
Inspired by the war photography she researched (and its violent prompts), Steyerl created a battle scene of her own with an AI image generator. Sited at Berlin’s Tempelhof Airport, she cheekily rendered it in the contemporary (and suddenly ubiquitous) ‘trending on artstation’ aesthetic.
Soundbite:
“Prompts can now be used as tools in machine learning based image creation. Neural networks, as you all know, are able to conjure up images from prompts or maybe from projective captions. This is why the whole topic of captions is so interesting to me. This basically reverses the DenseCap project, which extracts captions from images. This projects images from captions.”
Hito Steyerl, contrasting extracting information from images to projecting images with information
Soundbite:
“Which caption would create a prompt that would be able to project a future that leaves behind energy colonialism, data, and fossil extraction. We don’t know the caption, but we do know that once we find it, DenseCap will label it ‘the photo is [unk].’”
Hito Steyerl, on the kind of unknowability that we desperately need more of

Reference:
The culmination of several years of research by Goldsmith’s Creative & Social Computing Lecturer Dan McQuillan, Resisting AI: An Anti-Facist Approach to Artificial Intelligence (2022) dramatically intervenes with mainstream AI discourse. Challenging assumptions made by AI-boosters, McQuillan broadly argues for a humanistic use of AI to bolster social structures versus (technocratically) treating social formations as problems to be optimized. “Our ambition must stretch beyond the timid idea of AI governance, which accepts a priori what we’re already being subjected to, and instead look to create a transformative technical practice that supports the common good,” writes McQuillan in an excerpt published on Logic. In conversation after her talk, Steyerl recommends the book as offering solutions to help avoid the types of dilemmas discussed in her talk.
Soundbite:
“What Hito has done tonight, is set up an alternate history of AI for us. We’re told that AI started in 1956 in Dartmouth, Massachusetts, where a group of scientists thought they just needed a summer to crack AI—and here we are 70 years later LOL. Hito has read an existing history of the nation state, of energy futures and imaginaries, and histories of technology—and she’s projected them forward.”
Maya Indira Ganesh, encapsulating Steyerl’s talk

PROFILE:
Alex Hanna
Alex Hanna is Director of Research at the Distributed AI Research Institute (DAIR). Holding a PhD in sociology from the University of Wisconsin-Madison, her work centers on the data used in new computational technologies, and the ways in which these data exacerbate racial, gender, and class inequality. Hanna has published widely in journals including Mobilization, American Behavioral Scientist, and Big Data & Society.
Soundbite:
“I’m not sure there is something recoverable in the history of or from the body of techniques that have come to be thought of as artificial intelligence. Whichever way AI has or will go, the fact is that modern AI needs data to subsist and to perform even the most perfunctory of tasks.”
Alex Hanna, burning down the popular history of AI
Takeaway:
Hanna offers a history of AI that is not a tale about progress, computation, or simulating cognition, but one “littered with violence and warmaking.” A direct line can be drawn from gatherings of elite white males at American Ivy League schools to an accumulation of venture capital in Silicon Valley.
Takeaway:
Machine Learning datasets enact violence twice, first at the moment of capture and then again during the process of classification. That harm is then ‘baked in’ to future models created with the data.
Soundbite:
“Every modern AI technology, from OpenAI’s DALL-E and GPT-3 to the new open source StableDiffusion image generation model, requires web-scale data—typically drawn from the public web, with little regard to the people in those datasets.”
Alex Hanna, on how conversations about AI are conversations about data ethics
Soundbite:
“Saidiya Hartman defines critical fabulation as a method of writing and reading the archive. She says, the intention in Venus and Two Acts ‘isn’t as miraculous as reclaiming the lives of the enslaved, or redeeming the dead, but rather labelling to paint as full a picture of the lives of captives as possible.’”
Alex Hanna, drawing parallels between Saidiya Hartman’s work on the colonial archive of the transatlantic slave trade and the contemporary dataset

Soundbite:
“I’d like to note the necropolitical impulse of Paris is Burning, Venus Xtraveganza stands as an abject tale of death, her life as a coda to the story. In the penultimate scene of the film, Angie—who herself died of AIDS three years later—discusses Venus’ death as being about ‘being transsexual in New York City and surviving.”
Alex Hanna, on the Paris is Burning documentary’s extractive legacy

Reference:
A Jennie Livingston-directed documentary capturing the waning golden age of New York City’s drag balls, Paris is Burning was released in 1990 to widespread critical acclaim. Providing a window into drag and LGBTQ+ culture it documented the (then much more underground) drag scene and chronicled queer cultural innovation, ultimately making a career for Livingston without compensating its precarious subjects. Hanna deploys the film in a broader conversation about extractivism, archives, and datasets, underscoring the plight of one of it’s protagonists, Venus Xtraveganza (image), who brings vibrance to the film, but at its end, the trans latina sex worker is revealed to have been murdered.
Soundbite:
“I want to trouble Crawford and Paglen’s ImageNet archaeology. Who are the people retrieved in these datasets? And what productive work does the excavating of these AI datasets perform?”
Alex Hanna, foregrounding the personhood of the subjects of large image datasets (and practice of those that engage them)
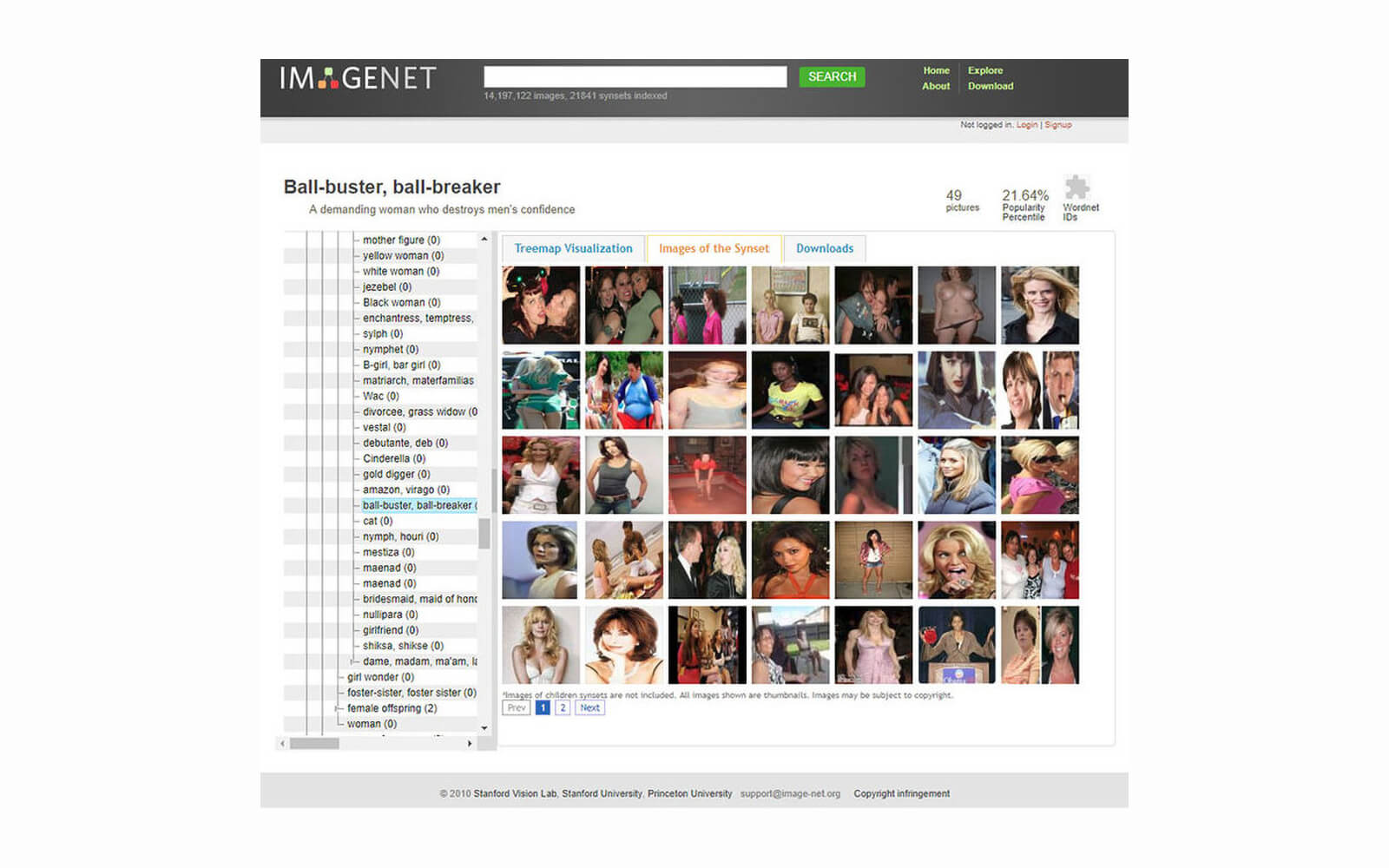
Reference:
A paper by AI researchers Kate Crawford and Trevor Paglen published by AI Now Institute in 2019, “Excavating AI“ digs into the politics of categorization in the ubiquitous ImageNet image database. With 15 million images, the database is widely used in visual object recognition software research, and one of the issues flagged by the authors is, the biases of classification render the datasets widespread use problematic. Crawford and Paglen explore this “sharp and dark turn“ of classification within the ‘person’ subclass in the database, collecting evidence of rampant sexism, misogyny, homophobia, and racism that creates conceptually suspect and ethically problematic distinctions between different types of bodies, genders, and identities.
Soundbite:
“With Lacework, Everest Pipkin taps into the roof of the matter: Machine learning datasets are a violent archive. Of faces, actions, of moments taken without context. Many of the frames which are available for people to contest being included in these archives are limited, be it informed consent as a scientific mechanism, data subjectivity within privacy and data regulation, and other liberal rights of protecting one’s likeness.”
Alex Hanna, outlining how much work remains to be done in ethical and consent-based data collection

Reference:
A 2020 project by Everest Pipkin, Lacework is a neural network reinscription of the MIT Moments in Time dataset. Taking that source collection of a million, labelled 3 second videos of dynamic scenes as a starting point, Pipkin slowed down the source clips and configured them to morph into one another, creating what they describe as a slow-motion “cascade of gradual, unfolding details.” The resulting work may be poetic, but Pipkin, who spent considerable time examining the source material, found dark corners of the dataset, stating they were exposed to “moments of questionable consent, including pornography. Racist and fascist imagery. Animal cruelty and torture … I saw dead bodies. I saw human lives end.”

Soundbite:
“It seems like there are some very fruitful overlaps between each of your discussions—as poetic inquiries, about missing historical information, about the violence of the archive and datasets, and about historical information and images as ways to talk about machine learning and AI.”
Nora N. Khan, highlighting commonalities between Steyerl and Hanna’s talks